Possible memleak in 3.3 HEAD
Hi, I think I'm having a memleak in 3.3's HEAD. My production system, which receives ~300 messages/s throughout the day (so ~26.4 million messages daily) leaks ~700MB of memory per day. I did some investigation, here are the details: # syslog-ng -V syslog-ng 3.3.0beta2 Installer-Version: 3.3.0beta2 Revision: ssh+git://bazsi@git.balabit//var/scm/git/syslog-ng/syslog-ng-ose--mainline--3.3#no_branch#d6eea6a1130f8343b6600976d9f2319f9ed86c88 Compile-Date: Sep 9 2011 16:32:59 Default-Modules: affile,afprog,afsocket,afuser,basicfuncs,csvparser,dbparser,syslogformat,afsql Available-Modules: syslogformat,affile,afmongodb,basicfuncs,csvparser,dbparser,afsql,convertfuncs,afprog,confgen,afsocket,afuser,afsocket-tls,dummy Enable-Debug: off Enable-GProf: off Enable-Memtrace: off Enable-IPv6: on Enable-Spoof-Source: on Enable-TCP-Wrapper: on Enable-Linux-Caps: on Enable-Pcre: off # My build is patched with: - https://github.com/algernon/libmongo-client/commit/93c5cff05feec5d7f421acfdf... (so it compiles on rhel5) - https://lists.balabit.hu/pipermail/syslog-ng/2011-April/016375.html (I need this feature) I don't think any of these is the reason, though. My test configuration is basically this: $ cat /etc/syslog-ng/syslog-ng.conf @version: 3.3 options { time_reap (1); log_fifo_size (100000); use_dns (no); use_fqdn (no); create_dirs (yes); keep_hostname (yes); log_msg_size(16384); owner ("root"); group ("root"); perm (0644); dir_owner ("root"); dir_group ("root"); dir_perm (0755); }; source s_www { syslog(ip(0.0.0.0) port(515) flags(no-multi-line) log_iw_size(6000) max-connections(30) tags("src.syslog", "src.port.515", "www", "www.accesslog")); }; filter f_svc_www_accesslog { tags("www.accesslog"); }; parser p_apache_split_vhost_access { csv-parser( columns("APACHE.ACCESS.VHOST", "APACHE.ACCESS.LOG_MESSAGE") flags(greedy) delimiters(" ") ); }; parser dbp_apache_split_vhost_access { db-parser( file("/etc/syslog-ng/pdb1.xml") ); }; destination d_access_split { file("/logs/$S_YEAR/$S_MONTH/$S_DAY/${APACHE.ACCESS.VHOST:-default}-access.log-${S_YEAR}${S_MONTH}${S_DAY}" template("${APACHE.ACCESS.LOG_MESSAGE}\n")); }; log { source(s_www); filter(f_svc_www_accesslog); parser(dbp_apache_split_vhost_access); destination(d_access_split); flags(final); }; $ Those two parsers (csv-parser and db-parser) are doing exactly the same, they split my Apache HTTPd access logs into two parts: first column (which is the vhost name) and the rest of the line. I have them both because I needed to know if that's a leak in any particular parser type. (Apparently not) I'm not very experienced with valgrind, but I did some tests, and what I've found is that the number of "definitely lost" blocks depends on the number of files created by d_access_split destination. So I took 10000 lines of some real httpd logs and did two tests: 1) replace real vhost names with completely random strings, to maximize number of files created by d_access_split 2) replace real vhost names with constant string, so my destination always writes to the same file. And this is what I got, using "G_SLICE=always-malloc valgrind --leak-check=full -v --show-reachable=yes --track-origins=yes --log-file=valgrind.log syslog-ng -F --no-caps -p /var/run/syslog-ng.pid" 1) random files: ==22416== 3,675,952 bytes in 9,989 blocks are definitely lost in loss record 578 of 578 ==22416== at 0x4021EC2: calloc (vg_replace_malloc.c:418) ==22416== by 0x40FF57D: g_malloc0 (in /lib/libglib-2.0.so.0.1200.3) ==22416== by 0x4052899: log_queue_fifo_new (logqueue-fifo.c:438) ==22416== by 0x4046057: log_dest_driver_acquire_queue_method (driver.c:153) ==22416== by 0x47081D1: affile_dw_init (driver.h:178) ==22416== by 0x4707C41: affile_dd_open_writer (logpipe.h:239) ==22416== by 0x405C258: main_loop_call (mainloop.c:145) ==22416== by 0x4707A6B: affile_dd_queue (affile.c:1127) ==22416== by 0x40451C8: log_dest_group_queue (logpipe.h:288) ==22416== by 0x404B9DD: log_multiplexer_queue (logpipe.h:288) ==22416== by 0x404EC16: log_parser_queue (logpipe.h:288) ==22416== by 0x4047473: log_filter_pipe_queue (logpipe.h:288) ==22416== ==22416== LEAK SUMMARY: ==22416== definitely lost: 3,676,156 bytes in 9,992 blocks ==22416== indirectly lost: 6,541 bytes in 56 blocks ==22416== possibly lost: 16,967 bytes in 117 blocks ==22416== still reachable: 76,908 bytes in 3,286 blocks ==22416== suppressed: 0 bytes in 0 blocks 2) single file (constant filename): ==19460== 368 bytes in 1 blocks are definitely lost in loss record 525 of 577 ==19460== at 0x4021EC2: calloc (vg_replace_malloc.c:418) ==19460== by 0x40FF57D: g_malloc0 (in /lib/libglib-2.0.so.0.1200.3) ==19460== by 0x4052899: log_queue_fifo_new (logqueue-fifo.c:438) ==19460== by 0x4046057: log_dest_driver_acquire_queue_method (driver.c:153) ==19460== by 0x47081D1: affile_dw_init (driver.h:178) ==19460== by 0x4707C41: affile_dd_open_writer (logpipe.h:239) ==19460== by 0x405C258: main_loop_call (mainloop.c:145) ==19460== by 0x4707A6B: affile_dd_queue (affile.c:1127) ==19460== by 0x40451C8: log_dest_group_queue (logpipe.h:288) ==19460== by 0x404B9DD: log_multiplexer_queue (logpipe.h:288) ==19460== by 0x404EC16: log_parser_queue (logpipe.h:288) ==19460== by 0x4047473: log_filter_pipe_queue (logpipe.h:288) (...) ==19460== LEAK SUMMARY: ==19460== definitely lost: 572 bytes in 4 blocks ==19460== indirectly lost: 6,541 bytes in 56 blocks ==19460== possibly lost: 12,919 bytes in 106 blocks ==19460== still reachable: 76,908 bytes in 3,286 blocks ==19460== suppressed: 0 bytes in 0 blocks Could anyone proficient in syslog-ng source code take a look on this? Can I do anything else to help you diagnose this? (I can provide complete valgrind output logs if this helps.) Also, I'll try to reproduce this on other versions later this week, unless someone fixes this earlier. :) Cheers, -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
Jakub Jankowski <shasta@toxcorp.com> writes:
Hi,
I think I'm having a memleak in 3.3's HEAD. My production system, which receives ~300 messages/s throughout the day (so ~26.4 million messages daily) leaks ~700MB of memory per day.
I did some investigation, here are the details:
# syslog-ng -V syslog-ng 3.3.0beta2 Installer-Version: 3.3.0beta2 Revision: ssh+git://bazsi@git.balabit//var/scm/git/syslog-ng/syslog-ng-ose--mainline--3.3#no_branch#d6eea6a1130f8343b6600976d9f2319f9ed86c88
Could you try with a more recent git checkout? Bazsi fixed a couple of memory leaks since d6eea6a1130f8343b6600976d9f2319f9ed86c88, and they should all be gone with the most recent git HEAD (0a3d844ff94a14d770bcdfa993f02e87e58a81f2).
My build is patched with: - https://github.com/algernon/libmongo-client/commit/93c5cff05feec5d7f421acfdf... (so it compiles on rhel5) - https://lists.balabit.hu/pipermail/syslog-ng/2011-April/016375.html (I need this feature)
I don't think any of these is the reason, though.
Correct, these aren't the reason for the leaks.
Those two parsers (csv-parser and db-parser) are doing exactly the same, they split my Apache HTTPd access logs into two parts: first column (which is the vhost name) and the rest of the line. I have them both because I needed to know if that's a leak in any particular parser type. (Apparently not) [...]
While I haven't looked at the valgrind logs yet, I'd still suggest trying the latest git HEAD, as there's a very high chance that it will not have the leaks. Hope that helps! (I'll have a look at the valgrind logs when time permits, thanks for investigating!) -- |8]
On Mon, 19 Sep 2011 07:13:28 +0200, Gergely Nagy wrote:
Jakub Jankowski <shasta@toxcorp.com> writes:
I think I'm having a memleak in 3.3's HEAD. My production system, which receives ~300 messages/s throughout the day (so ~26.4 million messages daily) leaks ~700MB of memory per day.
I did some investigation, here are the details:
# syslog-ng -V syslog-ng 3.3.0beta2 Installer-Version: 3.3.0beta2 Revision: ssh+git://bazsi@git.balabit//var/scm/git/syslog-ng/syslog-ng-ose--mainline--3.3#no_branch#d6eea6a1130f8343b6600976d9f2319f9ed86c88
Could you try with a more recent git checkout? Bazsi fixed a couple of memory leaks since d6eea6a1130f8343b6600976d9f2319f9ed86c88, and they should all be gone with the most recent git HEAD (0a3d844ff94a14d770bcdfa993f02e87e58a81f2).
Actually, the code I run is from HEAD, despite syslog-ng -V output. This is because of me having difficulties building directly from git checkout, I took 3.3.0beta2 tarball and applied all the patches that went into Bazsi's tree since 3.3.0beta2 tag. So, for example: $ grep -B 4 'nv_table_clone.*value_len' lib/logmsg.c if (!log_msg_chk_flag(self, LF_STATE_OWN_PAYLOAD)) { NVTable *payload = self->payload; self->payload = nv_table_clone(payload, name_len + value_len + 2); $ Which, if I'm right, comes from 951659d2cdda1a522740881354de25dcbd4e42ce, newer than that is only 0a3d844ff94a14d770bcdfa993f02e87e58a81f2 that adds nothing but a comment.
(I'll have a look at the valgrind logs when time permits, thanks for investigating!)
I'd be grateful, thanks. And sorry for misleading version output. Cheers, -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
Jakub Jankowski <shasta@toxcorp.com> writes:
Actually, the code I run is from HEAD, despite syslog-ng -V output. This is because of me having difficulties building directly from git checkout,
Oh, I see. What difficulties do you have, if I may ask? If it's a problem we can fix, then I think we should do that, so building from git becomes easier :)
Which, if I'm right, comes from 951659d2cdda1a522740881354de25dcbd4e42ce, newer than that is only 0a3d844ff94a14d770bcdfa993f02e87e58a81f2 that adds nothing but a comment.
Mhm, looks like you should have all the mem-leak patches.
(I'll have a look at the valgrind logs when time permits, thanks for investigating!)
I'd be grateful, thanks. And sorry for misleading version output.
While I didn't have the time to have a closer look, thinking ahead, if you could send me the full valgrind logs (off-list works too, if it's big or you don't want to send it to the list), that might make it easier for me to hunt down the leak. -- |8]
Monday 19 of September 2011 10:36:33 Gergely Nagy napisał(a):
Jakub Jankowski <shasta@toxcorp.com> writes:
Actually, the code I run is from HEAD, despite syslog-ng -V output. This is because of me having difficulties building directly from git checkout,
Oh, I see. What difficulties do you have, if I may ask? If it's a problem we can fix, then I think we should do that, so building from git becomes easier :)
I don't recall all my issues, but I'm pretty sure I had some with autogen.sh (autotools too old on el5), empty lib/ivykis/ after simple git clone, probably some more.
(I'll have a look at the valgrind logs when time permits, thanks for investigating!)
I'd be grateful, thanks. And sorry for misleading version output.
While I didn't have the time to have a closer look, thinking ahead, if you could send me the full valgrind logs (off-list works too, if it's big or you don't want to send it to the list), that might make it easier for me to hunt down the leak.
Since my report, I re-ran my tests on non-OpenVZ machine (to rule out possible, but unlikely, memory issues with OpenVZ kernel), and I ran the same tests on 3.2.2. It looks like 3.2.2 does not exhibit the leak I'm seeing on 3.3. Complete valgrind logs are available here: http://toxcorp.com/stuff/syslog-ng-leak/ Let me know if I can provide anything else to help with this. Thanks! -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
Jakub Jankowski <shasta@toxcorp.com> writes:
Monday 19 of September 2011 10:36:33 Gergely Nagy napisał(a):
Jakub Jankowski <shasta@toxcorp.com> writes:
Actually, the code I run is from HEAD, despite syslog-ng -V output. This is because of me having difficulties building directly from git checkout,
Oh, I see. What difficulties do you have, if I may ask? If it's a problem we can fix, then I think we should do that, so building from git becomes easier :)
I don't recall all my issues, but I'm pretty sure I had some with autogen.sh (autotools too old on el5), empty lib/ivykis/ after simple git clone, probably some more.
For the empty lib/ivykis/: git submodule init && git submodule update is the solution. I'll see if I can find an old enough system to break the autogen.sh in other interesting ways. Thanks for the pointer!
It looks like 3.2.2 does not exhibit the leak I'm seeing on 3.3. Complete valgrind logs are available here: http://toxcorp.com/stuff/syslog-ng-leak/
Thanks, I'll have a look! -- |8]
Monday 19 of September 2011 13:37:26 Gergely Nagy napisał(a):
Actually, the code I run is from HEAD, despite syslog-ng -V output. This is because of me having difficulties building directly from git checkout,
Oh, I see. What difficulties do you have, if I may ask? If it's a problem we can fix, then I think we should do that, so building from git becomes easier :)
I don't recall all my issues, but I'm pretty sure I had some with autogen.sh (autotools too old on el5), empty lib/ivykis/ after simple git clone, probably some more.
For the empty lib/ivykis/: git submodule init && git submodule update is the solution.
Thanks, this indeed fixed my total-git-newbie issue. :)
I'll see if I can find an old enough system to break the autogen.sh in other interesting ways. Thanks for the pointer!
You don't have to look far away :) CentOS5: Too old autotools. Well, you can run ./autogen.sh on a CentOS6 machine (with autoconf 2.63) and moved sources back to c5, only to know that: "syslog-ng requires bison 2.4 or later (traditional yacc is not enough). Your source tree seems to be from git, which doesn't have lib/cfg-grammar.c. Please install bison or use a distribution tarball." Regards, -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
Jakub Jankowski <shasta@toxcorp.com> writes:
I'll see if I can find an old enough system to break the autogen.sh in other interesting ways. Thanks for the pointer!
You don't have to look far away :) CentOS5: Too old autotools. Well, you can run ./autogen.sh on a CentOS6 machine (with autoconf 2.63) and moved sources back to c5, only to know that: "syslog-ng requires bison 2.4 or later (traditional yacc is not enough). Your source tree seems to be from git, which doesn't have lib/cfg-grammar.c. Please install bison or use a distribution tarball."
*chuckles* Thanks for the pointers! I suppose a regular make dist tarball (with generated stuff included) would be handy in these cases then? Then one would only need the various libraries, and not the extra tools for bootstrapping. I can set that up in a couple of minutes, I believe. -- |8]
Jakub Jankowski <shasta@toxcorp.com> writes:
It looks like 3.2.2 does not exhibit the leak I'm seeing on 3.3. Complete valgrind logs are available here: http://toxcorp.com/stuff/syslog-ng-leak/
Let me know if I can provide anything else to help with this. Thanks!
Quick update: I managed to reproduce the problem, and I can verify that this is present in current git head indeed. I used the following config: ,---- | @version: 3.3 | @include "scl.conf" | | options { | time-reap(1); | create-dirs(yes); | frac-digits(4); | }; | source s_network { | tcp(port (13514) tags("tcp-tag") flags(no-parse)); | }; | destination d_file { | file("/tmp/many-file/${FIRST:-default}-seq-${UNIXTIME}.log" | template("${REST}\n") | ); | }; | log { | source(s_network); | destination(d_file); | }; `---- Then do the following: for f in $(seq 1 10000); do echo "host-$f message $f" | nc localhost 13514; done I have an idea where to look further, will see how far I get. -- |8]
Hi, Thanks for the detailed problem description Jakub and the diagnosis Gergely. I've committed this patch to master: commit 2ed7f92153aec5e4e666ea17dcd8d2232a8e76f9 Author: Balazs Scheidler <bazsi@balabit.hu> Date: Tue Sep 27 20:12:24 2011 +0200 log_dest_driver_release_queue(): unref the queue even if no name is present This patch fixes a memory leak for file destinations, in which we leak all LogQueue instances, possibly containing data, which can become quite large, especially if a lot of log files are opened/closed continously. Reported-By: Jakub Jankowski <shasta@toxcorp.com> Cc: <syslog-ng-stable@balabit.hu> Cc: Gergely Nagy <algernon@balabit.hu> Signed-off-by: Balazs Scheidler <bazsi@balabit.hu> While I was there, I've also fixed a related problem, although less likely to happen: commit e224d45da2ecad68f7f9c44895849a0fc795aae5 Author: Balazs Scheidler <bazsi@balabit.hu> Date: Tue Sep 27 20:14:35 2011 +0200 log_dest_driver_acquire_queue(): make sure all dest drivers have a name The persist_name for acquire_queue() identifies the destination driver that would like to keep its queue kept accross reloads. File destinations didn't keep their queue, effectively causing file drivers to lose their queue accross reloads. This went unnoticed as LogWriter does one last time to flush everything out to the disk when reloading, but still it is more important to keep the queue properly. Cc: syslog-ng-stable@balabit.hu Signed-off-by: Balazs Scheidler <bazsi@balabit.hu> On Mon, 2011-09-19 at 14:16 +0200, Gergely Nagy wrote:
Jakub Jankowski <shasta@toxcorp.com> writes:
It looks like 3.2.2 does not exhibit the leak I'm seeing on 3.3. Complete valgrind logs are available here: http://toxcorp.com/stuff/syslog-ng-leak/
Let me know if I can provide anything else to help with this. Thanks!
Quick update: I managed to reproduce the problem, and I can verify that this is present in current git head indeed.
I used the following config:
,---- | @version: 3.3 | @include "scl.conf" | | options { | time-reap(1); | create-dirs(yes); | frac-digits(4); | }; | source s_network { | tcp(port (13514) tags("tcp-tag") flags(no-parse)); | }; | destination d_file { | file("/tmp/many-file/${FIRST:-default}-seq-${UNIXTIME}.log" | template("${REST}\n") | ); | }; | log { | source(s_network); | destination(d_file); | }; `----
Then do the following: for f in $(seq 1 10000); do echo "host-$f message $f" | nc localhost 13514; done
I have an idea where to look further, will see how far I get.
-- Bazsi
Hi, On Tue, 27 Sep 2011 20:16:29 +0200, Balazs Scheidler wrote:
Thanks for the detailed problem description Jakub and the diagnosis Gergely. I've committed this patch to master:
commit 2ed7f92153aec5e4e666ea17dcd8d2232a8e76f9 [...] commit e224d45da2ecad68f7f9c44895849a0fc795aae5
Sorry it took me so long to report back. Having issues building el5 package directly from git (see my other mails in this thread), I chose only to apply 2ed7f92153aec5e4e666ea17dcd8d2232a8e76f9 and e224d45da2ecad68f7f9c44895849a0fc795aae5 commits to the source I'm building from, which is essentially 0a3d844ff94a14d770bcdfa993f02e87e58a81f2. Unfortunately, those two patches do not seem to help, I'm still getting this in valgrind output on my test machine: ==17806== 419,076 bytes in 9,978 blocks are indirectly lost in loss record 581 of 582 ==17806== at 0x4022B83: malloc (vg_replace_malloc.c:195) ==17806== by 0x40FF615: g_malloc (in /lib/libglib-2.0.so.0.1200.3) ==17806== by 0x4112BC8: g_strdup (in /lib/libglib-2.0.so.0.1200.3) ==17806== by 0x40521D9: log_queue_init_instance (logqueue.c:188) ==17806== by 0x40528BA: log_queue_fifo_new (logqueue-fifo.c:440) ==17806== by 0x4045FF7: log_dest_driver_acquire_queue_method (driver.c:153) ==17806== by 0x4708219: affile_dw_init (driver.h:185) ==17806== by 0x4707C41: affile_dd_open_writer (logpipe.h:239) ==17806== by 0x405C268: main_loop_call (mainloop.c:145) ==17806== by 0x4707A6B: affile_dd_queue (affile.c:1127) ==17806== by 0x40451C8: log_dest_group_queue (logpipe.h:288) ==17806== by 0x404B9ED: log_multiplexer_queue (logpipe.h:288) ==17806== ==17806== 4,092,084 (3,673,008 direct, 419,076 indirect) bytes in 9,981 blocks are definitely lost in loss record 582 of 582 ==17806== at 0x4021EC2: calloc (vg_replace_malloc.c:418) ==17806== by 0x40FF57D: g_malloc0 (in /lib/libglib-2.0.so.0.1200.3) ==17806== by 0x40528A9: log_queue_fifo_new (logqueue-fifo.c:438) ==17806== by 0x4045FF7: log_dest_driver_acquire_queue_method (driver.c:153) ==17806== by 0x4708219: affile_dw_init (driver.h:185) ==17806== by 0x4707C41: affile_dd_open_writer (logpipe.h:239) ==17806== by 0x405C268: main_loop_call (mainloop.c:145) ==17806== by 0x4707A6B: affile_dd_queue (affile.c:1127) ==17806== by 0x40451C8: log_dest_group_queue (logpipe.h:288) ==17806== by 0x404B9ED: log_multiplexer_queue (logpipe.h:288) ==17806== by 0x404EC26: log_parser_queue (logpipe.h:288) ==17806== by 0x4047483: log_filter_pipe_queue (logpipe.h:288) ==17806== ==17806== LEAK SUMMARY: ==17806== definitely lost: 3,673,208 bytes in 9,984 blocks ==17806== indirectly lost: 425,595 bytes in 10,033 blocks ==17806== possibly lost: 20,425 bytes in 145 blocks ==17806== still reachable: 77,296 bytes in 3,288 blocks ==17806== suppressed: 0 bytes in 0 blocks So, either 1) those two patches are not sufficent to fix this bug, 2) those patches do not fix *this* bug, or 3) PEBKAC, and I'm doing something wrong (very likely!). Best way to see which one is true would be to build a package from git HEAD and run my tests again. Unfortunately, this is tricky on el5, I think I have to wait for Gergely to create a dist tarball like he promised :) Cheers, -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
Jakub Jankowski <shasta@toxcorp.com> writes:
Best way to see which one is true would be to build a package from git HEAD and run my tests again. Unfortunately, this is tricky on el5, I think I have to wait for Gergely to create a dist tarball like he promised :)
Quick update on this: tarball will be coming up shortly (in about ~10 hours, when I get to work). -- |8]
On 2011-10-03, Gergely Nagy wrote:
Jakub Jankowski <shasta@toxcorp.com> writes:
Best way to see which one is true would be to build a package from git HEAD and run my tests again. Unfortunately, this is tricky on el5, I think I have to wait for Gergely to create a dist tarball like he promised :)
Quick update on this: tarball will be coming up shortly (in about ~10 hours, when I get to work).
Great news, thanks in advance! -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
Jakub Jankowski <shasta@toxcorp.com> writes:
On 2011-10-03, Gergely Nagy wrote:
Jakub Jankowski <shasta@toxcorp.com> writes:
Best way to see which one is true would be to build a package from git HEAD and run my tests again. Unfortunately, this is tricky on el5, I think I have to wait for Gergely to create a dist tarball like he promised :)
Quick update on this: tarball will be coming up shortly (in about ~10 hours, when I get to work).
Great news, thanks in advance!
I set up a script to build daily make dist snapshots of the current git head. The script and the resulting tarballs are available at: http://packages.madhouse-project.org/syslog-ng/ The filename is syslog-ng-3.3-${UNIXTIME}-${COMMITID}.tar.gz, and syslog-ng-3.3-HEAD.tar.gz will always point to the latest tarball. -- |8]
On 2011-10-03, Gergely Nagy wrote:
Best way to see which one is true would be to build a package from git HEAD and run my tests again. Unfortunately, this is tricky on el5, I think I have to wait for Gergely to create a dist tarball like he promised :) Quick update on this: tarball will be coming up shortly (in about ~10 hours, when I get to work). I set up a script to build daily make dist snapshots of the current git head. The script and the resulting tarballs are available at: http://packages.madhouse-project.org/syslog-ng/ The filename is syslog-ng-3.3-${UNIXTIME}-${COMMITID}.tar.gz, and syslog-ng-3.3-HEAD.tar.gz will always point to the latest tarball.
Thank you very much. Works nicely, this definitely eases the building process in my environment. I'll be posting my findings shortly. Regards, -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
On Mon, 2011-10-03 at 00:14 +0200, Jakub Jankowski wrote:
Hi,
On Tue, 27 Sep 2011 20:16:29 +0200, Balazs Scheidler wrote:
Thanks for the detailed problem description Jakub and the diagnosis Gergely. I've committed this patch to master:
commit 2ed7f92153aec5e4e666ea17dcd8d2232a8e76f9 [...] commit e224d45da2ecad68f7f9c44895849a0fc795aae5
Sorry it took me so long to report back.
Having issues building el5 package directly from git (see my other mails in this thread), I chose only to apply 2ed7f92153aec5e4e666ea17dcd8d2232a8e76f9 and e224d45da2ecad68f7f9c44895849a0fc795aae5 commits to the source I'm building from, which is essentially 0a3d844ff94a14d770bcdfa993f02e87e58a81f2.
Unfortunately, those two patches do not seem to help, I'm still getting this in valgrind output on my test machine:
==17806== 419,076 bytes in 9,978 blocks are indirectly lost in loss record 581 of 582 ==17806== at 0x4022B83: malloc (vg_replace_malloc.c:195) ==17806== by 0x40FF615: g_malloc (in /lib/libglib-2.0.so.0.1200.3) ==17806== by 0x4112BC8: g_strdup (in /lib/libglib-2.0.so.0.1200.3) ==17806== by 0x40521D9: log_queue_init_instance (logqueue.c:188) ==17806== by 0x40528BA: log_queue_fifo_new (logqueue-fifo.c:440) ==17806== by 0x4045FF7: log_dest_driver_acquire_queue_method (driver.c:153) ==17806== by 0x4708219: affile_dw_init (driver.h:185) ==17806== by 0x4707C41: affile_dd_open_writer (logpipe.h:239) ==17806== by 0x405C268: main_loop_call (mainloop.c:145) ==17806== by 0x4707A6B: affile_dd_queue (affile.c:1127) ==17806== by 0x40451C8: log_dest_group_queue (logpipe.h:288) ==17806== by 0x404B9ED: log_multiplexer_queue (logpipe.h:288) ==17806== ==17806== 4,092,084 (3,673,008 direct, 419,076 indirect) bytes in 9,981 blocks are definitely lost in loss record 582 of 582 ==17806== at 0x4021EC2: calloc (vg_replace_malloc.c:418) ==17806== by 0x40FF57D: g_malloc0 (in /lib/libglib-2.0.so.0.1200.3) ==17806== by 0x40528A9: log_queue_fifo_new (logqueue-fifo.c:438) ==17806== by 0x4045FF7: log_dest_driver_acquire_queue_method (driver.c:153) ==17806== by 0x4708219: affile_dw_init (driver.h:185) ==17806== by 0x4707C41: affile_dd_open_writer (logpipe.h:239) ==17806== by 0x405C268: main_loop_call (mainloop.c:145) ==17806== by 0x4707A6B: affile_dd_queue (affile.c:1127) ==17806== by 0x40451C8: log_dest_group_queue (logpipe.h:288) ==17806== by 0x404B9ED: log_multiplexer_queue (logpipe.h:288) ==17806== by 0x404EC26: log_parser_queue (logpipe.h:288) ==17806== by 0x4047483: log_filter_pipe_queue (logpipe.h:288) ==17806== ==17806== LEAK SUMMARY: ==17806== definitely lost: 3,673,208 bytes in 9,984 blocks ==17806== indirectly lost: 425,595 bytes in 10,033 blocks ==17806== possibly lost: 20,425 bytes in 145 blocks ==17806== still reachable: 77,296 bytes in 3,288 blocks ==17806== suppressed: 0 bytes in 0 blocks
So, either 1) those two patches are not sufficent to fix this bug, 2) those patches do not fix *this* bug, or 3) PEBKAC, and I'm doing something wrong (very likely!).
Best way to see which one is true would be to build a package from git HEAD and run my tests again. Unfortunately, this is tricky on el5, I think I have to wait for Gergely to create a dist tarball like he promised :)
Strange, I've successfully reproduced the leak without the patches and they were fixed with them. Let's see if 3.3.1 solves the issue or not. -- Bazsi
On 2011-10-03, Balazs Scheidler wrote:
On Mon, 2011-10-03 at 00:14 +0200, Jakub Jankowski wrote:
On Tue, 27 Sep 2011 20:16:29 +0200, Balazs Scheidler wrote:
Having issues building el5 package directly from git (see my other mails in this thread), I chose only to apply 2ed7f92153aec5e4e666ea17dcd8d2232a8e76f9 and e224d45da2ecad68f7f9c44895849a0fc795aae5 commits to the source I'm building from, which is essentially 0a3d844ff94a14d770bcdfa993f02e87e58a81f2.
Unfortunately, those two patches do not seem to help, I'm still getting this in valgrind output on my test machine: [...] So, either 1) those two patches are not sufficent to fix this bug, 2) those patches do not fix *this* bug, or 3) PEBKAC, and I'm doing something wrong (very likely!).
Strange, I've successfully reproduced the leak without the patches and they were fixed with them. Let's see if 3.3.1 solves the issue or not.
As strange as it was, it seems really fixed with git HEAD. Using dist tarball Gergely provided (thanks again), I've built 70fa96f33c89ce2bb10d10aaa7ba0492764a441c and ran my tests. Results are comforting: $ grep -A 6 'LEAK SUMMARY' s3.3.1-70fa96f33c89ce2bb10d10aaa7ba0492764a441c-const.log ==28094== LEAK SUMMARY: ==28094== definitely lost: 101 bytes in 2 blocks ==28094== indirectly lost: 1,010 bytes in 21 blocks ==28094== possibly lost: 12,919 bytes in 106 blocks ==28094== still reachable: 76,628 bytes in 3,275 blocks ==28094== suppressed: 0 bytes in 0 blocks ==28094== $ grep -A 6 'LEAK SUMMARY' s3.3.1-70fa96f33c89ce2bb10d10aaa7ba0492764a441c-random.log ==30031== LEAK SUMMARY: ==30031== definitely lost: 101 bytes in 2 blocks ==30031== indirectly lost: 1,010 bytes in 21 blocks ==30031== possibly lost: 12,919 bytes in 106 blocks ==30031== still reachable: 76,628 bytes in 3,275 blocks ==30031== suppressed: 0 bytes in 0 blocks ==30031== $ It behaves the same no matter what files it creates. I'll soon see how it's doing on production systems. Thanks for the fix and help. Regards, -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
On Mon, 3 Oct 2011 14:34:13 +0200 (CEST), Jakub Jankowski wrote:
As strange as it was, it seems really fixed with git HEAD. Using dist tarball Gergely provided (thanks again), I've built 70fa96f33c89ce2bb10d10aaa7ba0492764a441c and ran my tests. Results are comforting:
$ grep -A 6 'LEAK SUMMARY' s3.3.1-70fa96f33c89ce2bb10d10aaa7ba0492764a441c-const.log ==28094== LEAK SUMMARY: ==28094== definitely lost: 101 bytes in 2 blocks ==28094== indirectly lost: 1,010 bytes in 21 blocks ==28094== possibly lost: 12,919 bytes in 106 blocks ==28094== still reachable: 76,628 bytes in 3,275 blocks ==28094== suppressed: 0 bytes in 0 blocks ==28094== $ grep -A 6 'LEAK SUMMARY' s3.3.1-70fa96f33c89ce2bb10d10aaa7ba0492764a441c-random.log ==30031== LEAK SUMMARY: ==30031== definitely lost: 101 bytes in 2 blocks ==30031== indirectly lost: 1,010 bytes in 21 blocks ==30031== possibly lost: 12,919 bytes in 106 blocks ==30031== still reachable: 76,628 bytes in 3,275 blocks ==30031== suppressed: 0 bytes in 0 blocks ==30031== $
It behaves the same no matter what files it creates. I'll soon see how it's doing on production systems. Thanks for the fix and help.
I think I spoke too soon. :-/ See attached cacti graph. This is basically an output of awk '/VmRSS:/ { $print $2*1024 }' /proc/$(cat /var/run/syslog-ng.pid)/status on git head ("3.3.1" ATM). There must be something else going on; any hints on how to diagnose this? Regards, -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
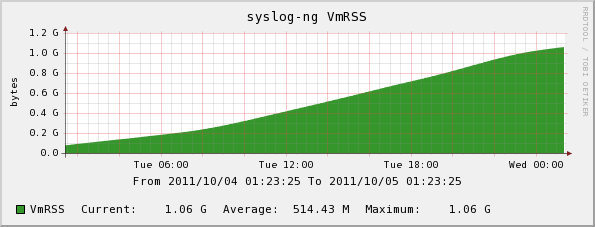{kind=link}
On Wed, 2011-10-05 at 01:44 +0200, Jakub Jankowski wrote:
On Mon, 3 Oct 2011 14:34:13 +0200 (CEST), Jakub Jankowski wrote:
As strange as it was, it seems really fixed with git HEAD. Using dist tarball Gergely provided (thanks again), I've built 70fa96f33c89ce2bb10d10aaa7ba0492764a441c and ran my tests. Results are comforting:
$ grep -A 6 'LEAK SUMMARY' s3.3.1-70fa96f33c89ce2bb10d10aaa7ba0492764a441c-const.log ==28094== LEAK SUMMARY: ==28094== definitely lost: 101 bytes in 2 blocks ==28094== indirectly lost: 1,010 bytes in 21 blocks ==28094== possibly lost: 12,919 bytes in 106 blocks ==28094== still reachable: 76,628 bytes in 3,275 blocks ==28094== suppressed: 0 bytes in 0 blocks ==28094== $ grep -A 6 'LEAK SUMMARY' s3.3.1-70fa96f33c89ce2bb10d10aaa7ba0492764a441c-random.log ==30031== LEAK SUMMARY: ==30031== definitely lost: 101 bytes in 2 blocks ==30031== indirectly lost: 1,010 bytes in 21 blocks ==30031== possibly lost: 12,919 bytes in 106 blocks ==30031== still reachable: 76,628 bytes in 3,275 blocks ==30031== suppressed: 0 bytes in 0 blocks ==30031== $
It behaves the same no matter what files it creates. I'll soon see how it's doing on production systems. Thanks for the fix and help.
I think I spoke too soon. :-/ See attached cacti graph. This is basically an output of awk '/VmRSS:/ { $print $2*1024 }' /proc/$(cat /var/run/syslog-ng.pid)/status on git head ("3.3.1" ATM). There must be something else going on; any hints on how to diagnose this?
It definitely seems to be a leak of some kind. If at all possible, running it for some time under valgrind like you did previously would be tremendous. If that's not possible, even generating a core file and running: strings core | sort | uniq -c And try to guess what it could be would probably help to narrow this down. -- Bazsi
On 2011-10-09, Balazs Scheidler wrote:
On Wed, 2011-10-05 at 01:44 +0200, Jakub Jankowski wrote:
On Mon, 3 Oct 2011 14:34:13 +0200 (CEST), Jakub Jankowski wrote:
I think I spoke too soon. :-/ See attached cacti graph. This is basically an output of awk '/VmRSS:/ { $print $2*1024 }' /proc/$(cat /var/run/syslog-ng.pid)/status on git head ("3.3.1" ATM). There must be something else going on; any hints on how to diagnose this?
It definitely seems to be a leak of some kind. If at all possible, running it for some time under valgrind like you did previously would be tremendous.
I've run half my "live" traffic for approx. 5 minutes through another node, with syslog-ng 3.3.1 running under valgrind. Log available at: http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-prod-half-5min.log Does it ring any bells (it doesn't for me). Should I test it longer? Regards, -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
On 2011-10-09, Jakub Jankowski wrote:
On 2011-10-09, Balazs Scheidler wrote:
On Wed, 2011-10-05 at 01:44 +0200, Jakub Jankowski wrote:
On Mon, 3 Oct 2011 14:34:13 +0200 (CEST), Jakub Jankowski wrote:
I think I spoke too soon. :-/ See attached cacti graph. This is basically an output of awk '/VmRSS:/ { $print $2*1024 }' /proc/$(cat /var/run/syslog-ng.pid)/status on git head ("3.3.1" ATM). There must be something else going on; any hints on how to diagnose this? It definitely seems to be a leak of some kind. If at all possible, running it for some time under valgrind like you did previously would be tremendous. I've run half my "live" traffic for approx. 5 minutes through another node, with syslog-ng 3.3.1 running under valgrind. Log available at: http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-prod-half-5min.log Does it ring any bells (it doesn't for me). Should I test it longer?
I've let it run ~83 minutes this time. No substantial changes in valgrind output: http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-prod-half-83min.log What baffles me is the number of errors related to "Syscall param epoll_ctl(event) points to uninitialised byte(s)". Anything else looks interesting? During this run, VmRSS kept rising, from: Sun Oct 9 21:44:51 CEST 2011; VmRSS: 3804 kB Sun Oct 9 21:44:52 CEST 2011; VmRSS: 3816 kB Sun Oct 9 21:44:53 CEST 2011; VmRSS: 3820 kB Sun Oct 9 21:44:54 CEST 2011; VmRSS: 3844 kB (...) to: Sun Oct 9 23:07:37 CEST 2011; VmRSS: 444760 kB Sun Oct 9 23:07:38 CEST 2011; VmRSS: 444764 kB Sun Oct 9 23:07:39 CEST 2011; VmRSS: 444764 kB Sun Oct 9 23:07:40 CEST 2011; VmRSS: 444880 kB Sun Oct 9 23:07:41 CEST 2011; VmRSS: 444896 kB Sun Oct 9 23:07:42 CEST 2011; VmRSS: 444896 kB Sun Oct 9 23:07:43 CEST 2011; VmRSS: 444896 kB Sun Oct 9 23:07:44 CEST 2011; VmRSS: 445332 kB HTH -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
On Sun, 2011-10-09 at 23:16 +0200, Jakub Jankowski wrote:
On 2011-10-09, Jakub Jankowski wrote:
On 2011-10-09, Balazs Scheidler wrote:
On Wed, 2011-10-05 at 01:44 +0200, Jakub Jankowski wrote:
On Mon, 3 Oct 2011 14:34:13 +0200 (CEST), Jakub Jankowski wrote:
I think I spoke too soon. :-/ See attached cacti graph. This is basically an output of awk '/VmRSS:/ { $print $2*1024 }' /proc/$(cat /var/run/syslog-ng.pid)/status on git head ("3.3.1" ATM). There must be something else going on; any hints on how to diagnose this? It definitely seems to be a leak of some kind. If at all possible, running it for some time under valgrind like you did previously would be tremendous. I've run half my "live" traffic for approx. 5 minutes through another node, with syslog-ng 3.3.1 running under valgrind. Log available at: http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-prod-half-5min.log Does it ring any bells (it doesn't for me). Should I test it longer?
I've let it run ~83 minutes this time. No substantial changes in valgrind output: http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-prod-half-83min.log What baffles me is the number of errors related to "Syscall param epoll_ctl(event) points to uninitialised byte(s)".
This is not nice, but shouldn't cause harm, but I'll recheck.
Anything else looks interesting?
During this run, VmRSS kept rising, from: Sun Oct 9 21:44:51 CEST 2011; VmRSS: 3804 kB Sun Oct 9 21:44:52 CEST 2011; VmRSS: 3816 kB Sun Oct 9 21:44:53 CEST 2011; VmRSS: 3820 kB Sun Oct 9 21:44:54 CEST 2011; VmRSS: 3844 kB (...) to: Sun Oct 9 23:07:37 CEST 2011; VmRSS: 444760 kB Sun Oct 9 23:07:38 CEST 2011; VmRSS: 444764 kB Sun Oct 9 23:07:39 CEST 2011; VmRSS: 444764 kB Sun Oct 9 23:07:40 CEST 2011; VmRSS: 444880 kB Sun Oct 9 23:07:41 CEST 2011; VmRSS: 444896 kB Sun Oct 9 23:07:42 CEST 2011; VmRSS: 444896 kB Sun Oct 9 23:07:43 CEST 2011; VmRSS: 444896 kB Sun Oct 9 23:07:44 CEST 2011; VmRSS: 445332 kB
Valgrind itself allocates memory to store the errors and warnings. Do you see this increase of memory usage without valgrind too? The valgrind output doesn't look bad, 97k leaked in 83 minutes, most of which seem to be one-off allocation which would be freed if syslog-ng was terminated properly. in use at exit: 97,299 bytes in 3,425 blocks I've rechecked the epoll_ctl() error, and as it seems vagrind doesn't like that some of the bytes in the epoll_event structure aren't initialized. However they don't need to be initialized, and I wouldn't want to add a memset() call. Hopefully valgrind will be fixed. It is possible to suppress these somehow. I've also read the complete log and I've found two minor leaks, both of which leak memory when processing SIGHUPs, I've fixed these: commit 0136e1b8a0460dd34be74c3fe6e202f971484be4 Author: Balazs Scheidler <bazsi@balabit.hu> Date: Thu Oct 13 15:28:57 2011 +0200 afsql: fixed a memory leak of the "indexes" array This bug caused some memory leaked at every SIGHUP. Reported-By: Jakub Jankowski <shasta@toxcorp.com> Signed-off-by: Balazs Scheidler <bazsi@balabit.hu> commit 5ef8dbba059d4670896e81f0bcf2bf63686f119b Author: Balazs Scheidler <bazsi@balabit.hu> Date: Thu Oct 13 15:28:17 2011 +0200 afuser: fixed the leakage of the username The afuser driver was leaking the name of the user, accumulating leaked some memory at every SIGHUP. Reported-By: Jakub Jankowski <shasta@toxcorp.com> Signed-off-by: Balazs Scheidler <bazsi@balabit.hu> The rest seems to be syslog-ng operating properly. Does it exhibit the same behaviour w/o valgrind? -- Bazsi
On Thu, 13 Oct 2011 15:32:27 +0200, Balazs Scheidler wrote:
Anything else looks interesting?
During this run, VmRSS kept rising, from: Sun Oct 9 21:44:51 CEST 2011; VmRSS: 3804 kB (...) to: Sun Oct 9 23:07:44 CEST 2011; VmRSS: 445332 kB
Valgrind itself allocates memory to store the errors and warnings. Do you see this increase of memory usage without valgrind too?
I did, that graph I sent here earlier was exactly the VmRSS of syslog-ng running, and as you've seen, it was rising. And it was running without valgrind :) I wanted to test this some more, but today I've noticed something odd. Since upgrading to 3.3.1, there is a strange behaviour of my system: if I reload syslog-ng, it spits out *tons* of similar messages: Internal error, duplicate configuration elements refer to the same persistent config; name='dd_queue(d_mesg,d_mesg#0)' As far as I can tell, this happens for every destination that was open: $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c 'dd_queue(d_mesg,d_mesg#0)' 186 $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c 'dd_queue(d_cron,d_cron#0)' 164 $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c '_errorlog#0' 62435 I'm pretty sure there are no duplicate configuration elements in my config, especially for those "standard" ones like d_mesg or d_cron: $ grep d_mesg /etc/syslog-ng/syslog-ng.conf destination d_mesg { file("/var/log/messages" group("root") flush_lines(1)); }; log { source(s_sys); filter(f_default); destination(d_mesg); }; $ grep messages /etc/syslog-ng/syslog-ng.conf destination d_mesg { file("/var/log/messages" group("root") flush_lines(1)); }; $ If there were, I'd get some errors at startup, right? Well, I don't. But what's most peculiar, is that after such reload, VmRSS stays roughly the same (at least it's not climbing like crazy).
I've also read the complete log and I've found two minor leaks, both of which leak memory when processing SIGHUPs, I've fixed these:
I've built a package with these two patches applied, and run it on my test system, to confirm this weird behaviour above. It still manifests. After a clean start, until there are logs to process, I can reload syslog-ng and there are no "Internal error" messages. As soon as I make my log relays send some messages to this test system, and try to reload it: boom, internal errors again. This is very weird, I don't recall this behaviour before. I know this description isn't the most precise one, but at this moment I had no time to investigate more. I promise I'll dig some more during next few days. But maybe even this much will help someone debug it. Regards, -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
On Fri, 14 Oct 2011 01:39:28 +0200, Jakub Jankowski wrote:
On Thu, 13 Oct 2011 15:32:27 +0200, Balazs Scheidler wrote:
Since upgrading to 3.3.1, there is a strange behaviour of my system: if I reload syslog-ng, it spits out *tons* of similar messages: Internal error, duplicate configuration elements refer to the same persistent config; name='dd_queue(d_mesg,d_mesg#0)'
As far as I can tell, this happens for every destination that was open: $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c 'dd_queue(d_mesg,d_mesg#0)' 186 $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c 'dd_queue(d_cron,d_cron#0)' 164 $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c '_errorlog#0' 62435
I'm pretty sure there are no duplicate configuration elements in my config, especially for those "standard" ones like d_mesg or d_cron:
$ grep d_mesg /etc/syslog-ng/syslog-ng.conf destination d_mesg { file("/var/log/messages" group("root") flush_lines(1)); }; log { source(s_sys); filter(f_default); destination(d_mesg); }; $ grep messages /etc/syslog-ng/syslog-ng.conf destination d_mesg { file("/var/log/messages" group("root") flush_lines(1)); }; $
If there were, I'd get some errors at startup, right? Well, I don't.
But what's most peculiar, is that after such reload, VmRSS stays roughly the same (at least it's not climbing like crazy).
I've also read the complete log and I've found two minor leaks, both of which leak memory when processing SIGHUPs, I've fixed these:
I've built a package with these two patches applied, and run it on my test system, to confirm this weird behaviour above. It still manifests. After a clean start, until there are logs to process, I can reload syslog-ng and there are no "Internal error" messages. As soon as I make my log relays send some messages to this test system, and try to reload it: boom, internal errors again.
This is very weird, I don't recall this behaviour before. I know this description isn't the most precise one, but at this moment I had no time to investigate more. I promise I'll dig some more during next few days. But maybe even this much will help someone debug it.
Ok, at least I managed to get valgrind output from SIGHUP processing. It's avaliable at http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-head-HUP.log This is for 3.3.1 with recent SIGHUP-leak-related patches applied. ==13436== LEAK SUMMARY: ==13436== definitely lost: 83,795 bytes in 1,698 blocks ==13436== indirectly lost: 1,012 bytes in 21 blocks ==13436== possibly lost: 13,153 bytes in 108 blocks ==13436== still reachable: 80,050 bytes in 3,278 blocks ==13436== suppressed: 0 bytes in 0 blocks But still I don't get why all of the sudden, "duplicate configuration elements" are logged on SIGHUP, but: - not on start - not if SIGHUP was received prior to any remote message Regards, -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
On Tue, 2011-10-18 at 23:15 +0200, Jakub Jankowski wrote:
On Fri, 14 Oct 2011 01:39:28 +0200, Jakub Jankowski wrote:
On Thu, 13 Oct 2011 15:32:27 +0200, Balazs Scheidler wrote:
Since upgrading to 3.3.1, there is a strange behaviour of my system: if I reload syslog-ng, it spits out *tons* of similar messages: Internal error, duplicate configuration elements refer to the same persistent config; name='dd_queue(d_mesg,d_mesg#0)'
As far as I can tell, this happens for every destination that was open: $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c 'dd_queue(d_mesg,d_mesg#0)' 186 $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c 'dd_queue(d_cron,d_cron#0)' 164 $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c '_errorlog#0' 62435
I'm pretty sure there are no duplicate configuration elements in my config, especially for those "standard" ones like d_mesg or d_cron:
$ grep d_mesg /etc/syslog-ng/syslog-ng.conf destination d_mesg { file("/var/log/messages" group("root") flush_lines(1)); }; log { source(s_sys); filter(f_default); destination(d_mesg); }; $ grep messages /etc/syslog-ng/syslog-ng.conf destination d_mesg { file("/var/log/messages" group("root") flush_lines(1)); }; $
If there were, I'd get some errors at startup, right? Well, I don't.
But what's most peculiar, is that after such reload, VmRSS stays roughly the same (at least it's not climbing like crazy).
I've also read the complete log and I've found two minor leaks, both of which leak memory when processing SIGHUPs, I've fixed these:
I've built a package with these two patches applied, and run it on my test system, to confirm this weird behaviour above. It still manifests. After a clean start, until there are logs to process, I can reload syslog-ng and there are no "Internal error" messages. As soon as I make my log relays send some messages to this test system, and try to reload it: boom, internal errors again.
This is very weird, I don't recall this behaviour before. I know this description isn't the most precise one, but at this moment I had no time to investigate more. I promise I'll dig some more during next few days. But maybe even this much will help someone debug it.
Ok, at least I managed to get valgrind output from SIGHUP processing. It's avaliable at http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-head-HUP.log This is for 3.3.1 with recent SIGHUP-leak-related patches applied.
==13436== LEAK SUMMARY: ==13436== definitely lost: 83,795 bytes in 1,698 blocks ==13436== indirectly lost: 1,012 bytes in 21 blocks ==13436== possibly lost: 13,153 bytes in 108 blocks ==13436== still reachable: 80,050 bytes in 3,278 blocks ==13436== suppressed: 0 bytes in 0 blocks
But still I don't get why all of the sudden, "duplicate configuration elements" are logged on SIGHUP, but: - not on start - not if SIGHUP was received prior to any remote message
Hi, Sorry for not answering your emails before, somehow I've missed them previously. Using your problem description I think I've found the issues that caused the leaks for you. The issue is a bit more involved than I like it at this stage (having released a stable version already), but anyway better late than never. The fix is a series of 5 patches (available on "master" branch): commit 73a8c48983319942f668080a19ec037d1aab22cf Author: Balazs Scheidler <bazsi@balabit.hu> Date: Mon Oct 31 10:06:01 2011 +0100 affile: release per-writer LogQueue instances during runtime Instead of keeping those queues around if a destination is reaped, allow them be freed. Also, make sure that file destinations have their queue restored accross SIGHUP in case they contain unflushed items. Reported-By: Jakub Jankowski <shasta@toxcorp.com> Signed-off-by: Balazs Scheidler <bazsi@balabit.hu> commit 040587ec5ec662756ac18eb7ff998af64359c3ba Author: Balazs Scheidler <bazsi@balabit.hu> Date: Mon Oct 31 10:03:18 2011 +0100 LogWriter: introduce log_writer_get_queue() method The new function returns the current LogQueue instance. Signed-off-by: Balazs Scheidler <bazsi@balabit.hu> commit df5cbb37116476bb0b03036f9837e345c8fdb151 Author: Balazs Scheidler <bazsi@balabit.hu> Date: Mon Oct 31 10:02:52 2011 +0100 LogQueue: added keep_on_reload() method This patch introduces a new member function for LogQueue instances. Its role is to indicate whether we prefer keeping that LogQueue instance around when reloading syslog-ng. The default FIFO implementation allows the core to free the queue if it has zero items. If the implementation doesn't supply such method, we default to keeping the queue around. Signed-off-by: Balazs Scheidler <bazsi@balabit.hu> commit 9d9679e9e13cecdba33b61d2d3da71869bb5490f Author: Balazs Scheidler <bazsi@balabit.hu> Date: Mon Oct 31 09:58:42 2011 +0100 LogDestDriver: properly maintain self->queues list in acquire/release The maintenance of the self->queues list was not complete, although new LogQueue instances acquired were added to the queue, their removal only worked in the log_dest_driver_deinit() function. With this change log_dest_driver_release_queue() can also be called explicitly by plugins, and the queues list will not become corrupted. Signed-off-by: Balazs Scheidler <bazsi@balabit.hu> commit 779e1e3fb0364b50f2125fd94eb927dda307886a Author: Balazs Scheidler <bazsi@balabit.hu> Date: Mon Oct 31 09:58:18 2011 +0100 driver: don't generate persist IDs for drivers that fail to specify one This seems to have been a bad idea. The only location this was used is the file() destination driver, but that has multiple queues, making the current default ID generation collide. Signed-off-by: Balazs Scheidler <bazsi@balabit.hu> Without these, file destinations would keep their queues around when reaped via time-reap(). Also the duplicate config elements should be fixed. Any feedback is appreciated. Thanks. -- Bazsi
On Mon, 31 Oct 2011 10:32:28 +0100, Balazs Scheidler wrote:
On Tue, 2011-10-18 at 23:15 +0200, Jakub Jankowski wrote:
On Fri, 14 Oct 2011 01:39:28 +0200, Jakub Jankowski wrote:
On Thu, 13 Oct 2011 15:32:27 +0200, Balazs Scheidler wrote:
Since upgrading to 3.3.1, there is a strange behaviour of my system: if I reload syslog-ng, it spits out *tons* of similar messages: Internal error, duplicate configuration elements refer to the same persistent config; name='dd_queue(d_mesg,d_mesg#0)' [...] Ok, at least I managed to get valgrind output from SIGHUP processing. It's avaliable at http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-head-HUP.log This is for 3.3.1 with recent SIGHUP-leak-related patches applied.
==13436== LEAK SUMMARY: ==13436== definitely lost: 83,795 bytes in 1,698 blocks ==13436== indirectly lost: 1,012 bytes in 21 blocks ==13436== possibly lost: 13,153 bytes in 108 blocks ==13436== still reachable: 80,050 bytes in 3,278 blocks ==13436== suppressed: 0 bytes in 0 blocks
But still I don't get why all of the sudden, "duplicate configuration elements" are logged on SIGHUP, but: - not on start - not if SIGHUP was received prior to any remote message
Using your problem description I think I've found the issues that caused the leaks for you. The issue is a bit more involved than I like it at this stage (having released a stable version already), but anyway better late than never.
The fix is a series of 5 patches (available on "master" branch): [...] Without these, file destinations would keep their queues around when reaped via time-reap(). Also the duplicate config elements should be fixed.
Any feedback is appreciated.
Thanks for your support. I've built current HEAD (using 3.3.1 tarball and applying git diff v3.3.1..master, because Gergely's automated dist tarball scripts did not have a chance to built what I need yet) and then ran my tests. My findings: 1. The "duplicate configuration elements" on HUP are gone indeed. Thanks. 2. There are still some leaks; one of which is definitely triggered by HUP. Full valgrind output files are available as: http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-60b5967-HUP.log http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-60b5967-noHUP.log Those are produced by using exactly the same input data, sent using: $ loggen --loop-reading --read-file access.random --active-connections 5 \ --number 10000 --interval 600 --syslog-proto 10.20.10.2 515 to syslog-ng running under valgrind on 10.20.10.2. access.random is a ~700k lines of apache access logs, with (prepended) virtualhost name replaced with some random data. If its any help, I could send you (off-list, due to privacy concerns) this source file along with my complete syslog-ng.conf. I hope that 3.3.2 will be The BugFreeiest Release of them all :-) Regards, -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
On Mon, 2011-10-31 at 12:17 +0100, Jakub Jankowski wrote:
On Mon, 31 Oct 2011 10:32:28 +0100, Balazs Scheidler wrote:
On Tue, 2011-10-18 at 23:15 +0200, Jakub Jankowski wrote:
On Fri, 14 Oct 2011 01:39:28 +0200, Jakub Jankowski wrote:
On Thu, 13 Oct 2011 15:32:27 +0200, Balazs Scheidler wrote:
Since upgrading to 3.3.1, there is a strange behaviour of my system: if I reload syslog-ng, it spits out *tons* of similar messages: Internal error, duplicate configuration elements refer to the same persistent config; name='dd_queue(d_mesg,d_mesg#0)' [...] Ok, at least I managed to get valgrind output from SIGHUP processing. It's avaliable at http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-head-HUP.log This is for 3.3.1 with recent SIGHUP-leak-related patches applied.
==13436== LEAK SUMMARY: ==13436== definitely lost: 83,795 bytes in 1,698 blocks ==13436== indirectly lost: 1,012 bytes in 21 blocks ==13436== possibly lost: 13,153 bytes in 108 blocks ==13436== still reachable: 80,050 bytes in 3,278 blocks ==13436== suppressed: 0 bytes in 0 blocks
But still I don't get why all of the sudden, "duplicate configuration elements" are logged on SIGHUP, but: - not on start - not if SIGHUP was received prior to any remote message
Using your problem description I think I've found the issues that caused the leaks for you. The issue is a bit more involved than I like it at this stage (having released a stable version already), but anyway better late than never.
The fix is a series of 5 patches (available on "master" branch): [...] Without these, file destinations would keep their queues around when reaped via time-reap(). Also the duplicate config elements should be fixed.
Any feedback is appreciated.
Thanks for your support. I've built current HEAD (using 3.3.1 tarball and applying git diff v3.3.1..master, because Gergely's automated dist tarball scripts did not have a chance to built what I need yet) and then ran my tests.
My findings:
1. The "duplicate configuration elements" on HUP are gone indeed. Thanks. 2. There are still some leaks; one of which is definitely triggered by HUP. Full valgrind output files are available as: http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-60b5967-HUP.log http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-60b5967-noHUP.log Those are produced by using exactly the same input data, sent using: $ loggen --loop-reading --read-file access.random --active-connections 5 \ --number 10000 --interval 600 --syslog-proto 10.20.10.2 515 to syslog-ng running under valgrind on 10.20.10.2.
access.random is a ~700k lines of apache access logs, with (prepended) virtualhost name replaced with some random data. If its any help, I could send you (off-list, due to privacy concerns) this source file along with my complete syslog-ng.conf.
I hope that 3.3.2 will be The BugFreeiest Release of them all :-)
Thanks for the detailed diagnosis, there was indeed a leak which can multiply on reload for each open (at the time of the reload), macro-based destination file. commit 9e7f9258b03c58701be40d40f9708bb3a9c56625 Author: Balazs Scheidler <bazsi@balabit.hu> Date: Mon Oct 31 22:14:05 2011 +0100 log_writer_set_options: fixed a memory leak log_writer_set_options() will be called possibly multiple times on the same instance, but the code didn't check if stats_id or stats_instance were already set. If they were, their old value was forgotten, thus leaked. Reported-By: Jakub Jankowski <shasta@toxcorp.com> Signed-off-by: Balazs Scheidler <bazsi@balabit.hu> -- Bazsi
On Mon, 31 Oct 2011 22:16:21 +0100, Balazs Scheidler wrote:
On Mon, 2011-10-31 at 12:17 +0100, Jakub Jankowski wrote:
2. There are still some leaks; one of which is definitely triggered by HUP. Full valgrind output files are available as: http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-60b5967-HUP.log http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-60b5967-noHUP.log [...] Thanks for the detailed diagnosis, there was indeed a leak which can multiply on reload for each open (at the time of the reload), macro-based destination file.
commit 9e7f9258b03c58701be40d40f9708bb3a9c56625
I can confirm that current HEAD does not exhibit this leak any longer: ==25823== LEAK SUMMARY: ==25823== definitely lost: 637 bytes in 14 blocks ==25823== indirectly lost: 0 bytes in 0 blocks ==25823== possibly lost: 13,071 bytes in 107 blocks ==25823== still reachable: 78,991 bytes in 3,277 blocks ==25823== suppressed: 0 bytes in 0 blocks I've updated my production systems to 9e7f9258b and will observe its behaviour over the next few days (but even 60b5967 looked promising). Thanks for your help, it is much appreciated. Also sorry for being so obtrusive about this issue :^) Regards, -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
On Tue, 1 Nov 2011 01:18:38 +0100, Jakub Jankowski wrote:
On Mon, 31 Oct 2011 22:16:21 +0100, Balazs Scheidler wrote:
On Mon, 2011-10-31 at 12:17 +0100, Jakub Jankowski wrote:
2. There are still some leaks; one of which is definitely triggered by HUP. Full valgrind output files are available as: http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-60b5967-HUP.log http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-60b5967-noHUP.log [...] Thanks for the detailed diagnosis, there was indeed a leak which can multiply on reload for each open (at the time of the reload), macro-based destination file.
commit 9e7f9258b03c58701be40d40f9708bb3a9c56625
I can confirm that current HEAD does not exhibit this leak any longer:
==25823== LEAK SUMMARY: ==25823== definitely lost: 637 bytes in 14 blocks ==25823== indirectly lost: 0 bytes in 0 blocks ==25823== possibly lost: 13,071 bytes in 107 blocks ==25823== still reachable: 78,991 bytes in 3,277 blocks ==25823== suppressed: 0 bytes in 0 blocks
I've updated my production systems to 9e7f9258b and will observe its behaviour over the next few days (but even 60b5967 looked promising).
I've been running 9e7f9258b for the past ~12 hours and VmRSS grew by about 1MB, which is a huge improvement over what I experienced earlier (roughly 1GB/day). Thanks again. -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
On Tue, 2011-11-01 at 12:33 +0100, Jakub Jankowski wrote:
On Tue, 1 Nov 2011 01:18:38 +0100, Jakub Jankowski wrote:
On Mon, 31 Oct 2011 22:16:21 +0100, Balazs Scheidler wrote:
On Mon, 2011-10-31 at 12:17 +0100, Jakub Jankowski wrote:
2. There are still some leaks; one of which is definitely triggered by HUP. Full valgrind output files are available as: http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-60b5967-HUP.log http://toxcorp.com/stuff/syslog-ng-leak/s3.3.1-60b5967-noHUP.log [...] Thanks for the detailed diagnosis, there was indeed a leak which can multiply on reload for each open (at the time of the reload), macro-based destination file.
commit 9e7f9258b03c58701be40d40f9708bb3a9c56625
I can confirm that current HEAD does not exhibit this leak any longer:
==25823== LEAK SUMMARY: ==25823== definitely lost: 637 bytes in 14 blocks ==25823== indirectly lost: 0 bytes in 0 blocks ==25823== possibly lost: 13,071 bytes in 107 blocks ==25823== still reachable: 78,991 bytes in 3,277 blocks ==25823== suppressed: 0 bytes in 0 blocks
I've updated my production systems to 9e7f9258b and will observe its behaviour over the next few days (but even 60b5967 looked promising).
I've been running 9e7f9258b for the past ~12 hours and VmRSS grew by about 1MB, which is a huge improvement over what I experienced earlier (roughly 1GB/day).
Thanks for reporting back. Having this nailed I think I go on to prepare 3.3.2 then. -- Bazsi
On Fri, 2011-10-14 at 01:39 +0200, Jakub Jankowski wrote:
On Thu, 13 Oct 2011 15:32:27 +0200, Balazs Scheidler wrote:
Anything else looks interesting?
During this run, VmRSS kept rising, from: Sun Oct 9 21:44:51 CEST 2011; VmRSS: 3804 kB (...) to: Sun Oct 9 23:07:44 CEST 2011; VmRSS: 445332 kB
Valgrind itself allocates memory to store the errors and warnings. Do you see this increase of memory usage without valgrind too?
I did, that graph I sent here earlier was exactly the VmRSS of syslog-ng running, and as you've seen, it was rising. And it was running without valgrind :) I wanted to test this some more, but today I've noticed something odd.
Since upgrading to 3.3.1, there is a strange behaviour of my system: if I reload syslog-ng, it spits out *tons* of similar messages: Internal error, duplicate configuration elements refer to the same persistent config; name='dd_queue(d_mesg,d_mesg#0)'
As far as I can tell, this happens for every destination that was open: $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c 'dd_queue(d_mesg,d_mesg#0)' 186 $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c 'dd_queue(d_cron,d_cron#0)' 164 $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c '_errorlog#0' 62435
I'm pretty sure there are no duplicate configuration elements in my config, especially for those "standard" ones like d_mesg or d_cron:
$ grep d_mesg /etc/syslog-ng/syslog-ng.conf destination d_mesg { file("/var/log/messages" group("root") flush_lines(1)); }; log { source(s_sys); filter(f_default); destination(d_mesg); }; $ grep messages /etc/syslog-ng/syslog-ng.conf destination d_mesg { file("/var/log/messages" group("root") flush_lines(1)); }; $
If there were, I'd get some errors at startup, right? Well, I don't.
But what's most peculiar, is that after such reload, VmRSS stays roughly the same (at least it's not climbing like crazy).
I've also read the complete log and I've found two minor leaks, both of which leak memory when processing SIGHUPs, I've fixed these:
I've built a package with these two patches applied, and run it on my test system, to confirm this weird behaviour above. It still manifests. After a clean start, until there are logs to process, I can reload syslog-ng and there are no "Internal error" messages. As soon as I make my log relays send some messages to this test system, and try to reload it: boom, internal errors again.
This is very weird, I don't recall this behaviour before. I know this description isn't the most precise one, but at this moment I had no time to investigate more. I promise I'll dig some more during next few days. But maybe even this much will help someone debug it.
Ops, I've missed this email until now. I'm trying to fix this issue before releasing 3.3.2. -- Bazsi
R ----- Original Message ----- From: Balazs Scheidler [mailto:bazsi@balabit.hu] Sent: Monday, October 31, 2011 04:09 AM To: Syslog-ng users' and developers' mailing list <syslog-ng@lists.balabit.hu> Subject: Re: [syslog-ng] Possible memleak in 3.3 HEAD On Fri, 2011-10-14 at 01:39 +0200, Jakub Jankowski wrote:
On Thu, 13 Oct 2011 15:32:27 +0200, Balazs Scheidler wrote:
Anything else looks interesting?
During this run, VmRSS kept rising, from: Sun Oct 9 21:44:51 CEST 2011; VmRSS: 3804 kB (...) to: Sun Oct 9 23:07:44 CEST 2011; VmRSS: 445332 kB
Valgrind itself allocates memory to store the errors and warnings. Do you see this increase of memory usage without valgrind too?
I did, that graph I sent here earlier was exactly the VmRSS of syslog-ng running, and as you've seen, it was rising. And it was running without valgrind :) I wanted to test this some more, but today I've noticed something odd.
Since upgrading to 3.3.1, there is a strange behaviour of my system: if I reload syslog-ng, it spits out *tons* of similar messages: Internal error, duplicate configuration elements refer to the same persistent config; name='dd_queue(d_mesg,d_mesg#0)'
As far as I can tell, this happens for every destination that was open: $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c 'dd_queue(d_mesg,d_mesg#0)' 186 $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c 'dd_queue(d_cron,d_cron#0)' 164 $ grep '^Oct 14 00:00:03' /var/log/messages | grep -c '_errorlog#0' 62435
I'm pretty sure there are no duplicate configuration elements in my config, especially for those "standard" ones like d_mesg or d_cron:
$ grep d_mesg /etc/syslog-ng/syslog-ng.conf destination d_mesg { file("/var/log/messages" group("root") flush_lines(1)); }; log { source(s_sys); filter(f_default); destination(d_mesg); }; $ grep messages /etc/syslog-ng/syslog-ng.conf destination d_mesg { file("/var/log/messages" group("root") flush_lines(1)); }; $
If there were, I'd get some errors at startup, right? Well, I don't.
But what's most peculiar, is that after such reload, VmRSS stays roughly the same (at least it's not climbing like crazy).
I've also read the complete log and I've found two minor leaks, both of which leak memory when processing SIGHUPs, I've fixed these:
I've built a package with these two patches applied, and run it on my test system, to confirm this weird behaviour above. It still manifests. After a clean start, until there are logs to process, I can reload syslog-ng and there are no "Internal error" messages. As soon as I make my log relays send some messages to this test system, and try to reload it: boom, internal errors again.
This is very weird, I don't recall this behaviour before. I know this description isn't the most precise one, but at this moment I had no time to investigate more. I promise I'll dig some more during next few days. But maybe even this much will help someone debug it.
Ops, I've missed this email until now. I'm trying to fix this issue before releasing 3.3.2. -- Bazsi ______________________________________________________________________________ Member info: https://lists.balabit.hu/mailman/listinfo/syslog-ng Documentation: http://www.balabit.com/support/documentation/?product=syslog-ng FAQ: http://www.balabit.com/wiki/syslog-ng-faq
Hi Everyone, I've recently found a memory leak in version 3.0.4 that occurs if the configuration file contains any duplicate entries for the following items: sources, destinations, filters, rewrites, parsers. The leak occurs when the configuration is loaded or reloaded due to a SIGHUP. The config items are stored in a hash table (hash is based on the name of the filter). It seems that in the hashing utility if a request is made to add an item with the same key as a previous item the old item is replaced by the new item (libglib2-2.24.1/glib/ghash.c, g_hash_table_insert()). This is where the memory gets lost. Syslog-ng is not notified that the item has been discarded. I considered several possibilities to fix this issue. There are other modes for the hash utility where destroy functions can be setup to deal with the discarded items, but these are orientated around discarding the old item. I thought this was risky as the item may already be referenced by other items. I'm not sure if this case??? In the end I decided to check for the presence of a duplicate in the table before adding the new item. If an existing item is found I discard the new item. While I realise 3.0.4 is quite old now and perhaps not supported, it looks like the same basic mechanism is still used in OSE 3.3.1, so I'm submitting my code changes for consideration. I haven't tried reproducing the issue on 3.3.1. Any comments? Regards Anthony Lineham
On Thu, 2011-10-13 at 09:47 +1300, anthony lineham wrote:
Hi Everyone,
I've recently found a memory leak in version 3.0.4 that occurs if the configuration file contains any duplicate entries for the following items: sources, destinations, filters, rewrites, parsers. The leak occurs when the configuration is loaded or reloaded due to a SIGHUP. The config items are stored in a hash table (hash is based on the name of the filter). It seems that in the hashing utility if a request is made to add an item with the same key as a previous item the old item is replaced by the new item (libglib2-2.24.1/glib/ghash.c, g_hash_table_insert()). This is where the memory gets lost. Syslog-ng is not notified that the item has been discarded.
I considered several possibilities to fix this issue. There are other modes for the hash utility where destroy functions can be setup to deal with the discarded items, but these are orientated around discarding the old item. I thought this was risky as the item may already be referenced by other items. I'm not sure if this case??? In the end I decided to check for the presence of a duplicate in the table before adding the new item. If an existing item is found I discard the new item.
While I realise 3.0.4 is quite old now and perhaps not supported, it looks like the same basic mechanism is still used in OSE 3.3.1, so I'm submitting my code changes for consideration. I haven't tried reproducing the issue on 3.3.1.
Any comments?
Regards Anthony Lineham
comment on figuring out the bug: Awesome! :) comment on your solution to test first: seems correct to me comment on the code: Would it be better coding form to create a parameterized function from the code block, and then just call it six times with 'source', 'rewrite', etc., rather than cut and paste essentially the same code block six times in it's entirety? Seems like it might be a bit cleaner and easier to maintain. Or was there a reason I'm not aware of as to why it needs to be this way?
On 10/15/2011 at 12:36 PM, in message <1318635416.18436.11.camel@monolith.infinux.org>, Christopher Barry <christopher.barry@rackwareinc.com> wrote: On Thu, 2011-10-13 at 09:47 +1300, anthony lineham wrote: Hi Everyone,
I've recently found a memory leak in version 3.0.4 that occurs if the configuration file contains any duplicate entries for the following items: sources, destinations, filters, rewrites, parsers. The leak occurs when the configuration is loaded or reloaded due to a SIGHUP. The config items are stored in a hash table (hash is based on the name of the filter). It seems that in the hashing utility if a request is made to add an item with the same key as a previous item the old item is replaced by the new item (libglib2-2.24.1/glib/ghash.c, g_hash_table_insert()). This is where the memory gets lost. Syslog-ng is not notified that the item has been discarded.
I considered several possibilities to fix this issue. There are other modes for the hash utility where destroy functions can be setup to deal with the discarded items, but these are orientated around discarding the old item. I thought this was risky as the item may already be referenced by other items. I'm not sure if this case??? In the end I decided to check for the presence of a duplicate in the table before adding the new item. If an existing item is found I discard the new item.
While I realise 3.0.4 is quite old now and perhaps not supported, it looks like the same basic mechanism is still used in OSE 3.3.1, so I'm submitting my code changes for consideration. I haven't tried reproducing the issue on 3.3.1.
Any comments?
Regards Anthony Lineham
comment on figuring out the bug: Awesome! :)
comment on your solution to test first: seems correct to me
comment on the code: Would it be better coding form to create a parameterized function from the code block, and then just call it six times with 'source', 'rewrite', etc., rather than cut and paste essentially the same code block six times in it's entirety? Seems like it might be a bit cleaner and easier to maintain. Or was there a reason I'm not aware of as to why it needs to be this way?
Hi Christopher, Thanks for the comments. You're right, there is some code replication going on there. However, there are actually 3 different types involved: pipes, process rules and templates. So, to boil it down to one function might be a bit messy (open to suggestions!). Another option would be to create a function for each of the 3 types. This would certainly reduce the replication and I think it would be worthwhile - for the reasons you've stated. For some reason I like the ability to easily report the type of item that is a duplicate, but I've attached a patch which sacrifices that ability in the interests of reducing the replication. Note: I've compiled this code but I haven't re-run my tests on it. Regards Anthony
Hi Anthony, Sorry for not answering any sooner, this email has gone the same fate as Jakub's, therefore I didn't read it when it was posted. Thanks for noticing this problem, tracking it down and posting a patch. I decided to use a different implementation, which uses the configuration parser framework to report problems and committed this patch: commit b061328b3e0d3b466ac29ef4e1b3ee384b7130b0 Author: Balazs Scheidler <bazsi@balabit.hu> Date: Mon Oct 31 16:33:32 2011 +0100 configuration: report duplicate configuration elements Previously if a configuration element name was used twice, the 2nd would be used and some memory was leaked on every reload. This patch changes that by reporting duplicate IDs as configuration errors. A patch was posted by Anthony, but a different implementation was used instead. Reported-By: anthony lineham <anthony.lineham@alliedtelesis.co.nz> Signed-off-by: Balazs Scheidler <bazsi@balabit.hu> It reports duplicate config elements like this: /------------ |Error parsing config, duplicate destination in etc/syslog-ng.conf at line 29, column 13: | |destination d_file { | ^^^^^^ | |syslog-ng documentation: http://www.balabit.com/support/documentation/?product=syslog-ng |mailing list: https://lists.balabit.hu/mailman/listinfo/syslog-ng \------------ This also means, that such problems will prevent syslog-ng to start up, but I'd say anyone using duplicate config elements should take notice. :) The leak should also be fixed by my patch too. Thanks again. On Thu, 2011-10-13 at 09:47 +1300, anthony lineham wrote:
Hi Everyone,
I've recently found a memory leak in version 3.0.4 that occurs if the configuration file contains any duplicate entries for the following items: sources, destinations, filters, rewrites, parsers. The leak occurs when the configuration is loaded or reloaded due to a SIGHUP. The config items are stored in a hash table (hash is based on the name of the filter). It seems that in the hashing utility if a request is made to add an item with the same key as a previous item the old item is replaced by the new item (libglib2-2.24.1/glib/ghash.c, g_hash_table_insert()). This is where the memory gets lost. Syslog-ng is not notified that the item has been discarded.
I considered several possibilities to fix this issue. There are other modes for the hash utility where destroy functions can be setup to deal with the discarded items, but these are orientated around discarding the old item. I thought this was risky as the item may already be referenced by other items. I'm not sure if this case??? In the end I decided to check for the presence of a duplicate in the table before adding the new item. If an existing item is found I discard the new item.
While I realise 3.0.4 is quite old now and perhaps not supported, it looks like the same basic mechanism is still used in OSE 3.3.1, so I'm submitting my code changes for consideration. I haven't tried reproducing the issue on 3.3.1.
Any comments?
-- Bazsi
Hi Bazsi, Thanks for the follow up. It makes sense to be trapping the config error as soon as possible, and as you said, users should be encouraged to have sensible configurations. Regards Anthony
On 11/1/2011 at 04:37 AM, in message <1320075450.22972.127.camel@bzorp>, Balazs Scheidler <bazsi@balabit.hu> wrote: Hi Anthony,
Sorry for not answering any sooner, this email has gone the same fate as Jakub's, therefore I didn't read it when it was posted.
Thanks for noticing this problem, tracking it down and posting a patch. I decided to use a different implementation, which uses the configuration parser framework to report problems and committed this patch:
commit b061328b3e0d3b466ac29ef4e1b3ee384b7130b0 Author: Balazs Scheidler <bazsi@balabit.hu> Date: Mon Oct 31 16:33:32 2011 +0100
configuration: report duplicate configuration elements
Previously if a configuration element name was used twice, the 2nd would be used and some memory was leaked on every reload.
This patch changes that by reporting duplicate IDs as configuration errors.
A patch was posted by Anthony, but a different implementation was used instead.
Reported-By: anthony lineham <anthony.lineham@alliedtelesis.co.nz> Signed-off-by: Balazs Scheidler <bazsi@balabit.hu>
It reports duplicate config elements like this:
/------------ |Error parsing config, duplicate destination in etc/syslog-ng.conf at line 29, column 13: | |destination d_file { | ^^^^^^ | |syslog-ng documentation: http://www.balabit.com/support/documentation/?product=syslog-ng |mailing list: https://lists.balabit.hu/mailman/listinfo/syslog-ng \- -----------
This also means, that such problems will prevent syslog-ng to start up, but I'd say anyone using duplicate config elements should take notice. :)
The leak should also be fixed by my patch too.
Thanks again.
On Thu, 2011-10-13 at 09:47 +1300, anthony lineham wrote:
Hi Everyone,
I've recently found a memory leak in version 3.0.4 that occurs if the configuration file contains any duplicate entries for the following items: sources, destinations, filters, rewrites, parsers. The leak occurs when the configuration is loaded or reloaded due to a SIGHUP. The config items are stored in a hash table (hash is based on the name of the filter). It seems that in the hashing utility if a request is made to add an item with the same key as a previous item the old item is replaced by the new item (libglib2-2.24.1/glib/ghash.c, g_hash_table_insert()). This is where the memory gets lost. Syslog-ng is not notified that the item has been discarded.
I considered several possibilities to fix this issue. There are other modes for the hash utility where destroy functions can be setup to deal with the discarded items, but these are orientated around discarding the old item. I thought this was risky as the item may already be referenced by other items. I'm not sure if this case??? In the end I decided to check for the presence of a duplicate in the table before adding the new item. If an existing item is found I discard the new item.
While I realise 3.0.4 is quite old now and perhaps not supported, it looks like the same basic mechanism is still used in OSE 3.3.1, so I'm submitting my code changes for consideration. I haven't tried reproducing the issue on 3.3.1.
Any comments?
Sorry if this is a duplicate, I'm not sure it made it to the list on my first try...
commit b061328b3e0d3b466ac29ef4e1b3ee384b7130b0 Author: Balazs Scheidler <bazsi at balabit.hu> Date: Mon Oct 31 16:33:32 2011 +0100
configuration: report duplicate configuration elements
Previously if a configuration element name was used twice, the 2nd would be used and some memory was leaked on every reload.
This patch changes that by reporting duplicate IDs as configuration errors.
A patch was posted by Anthony, but a different implementation was used instead.
Reported-By: anthony lineham <anthony.lineham at alliedtelesis.co.nz> Signed-off-by: Balazs Scheidler <bazsi at balabit.hu>
Does this patch break the behavior described in the documentation for 3.3.1?
If an object is defined twice (for example the original syslog-ng configuration file and the file imported into this configuration file both define the same option, source, or other object), then the object that is defined later in the configuration file will be effective. For example, if you set a global option at the beginning of the configuration file, and later include a file that defines the same option with a different value, then the option defined in the imported file will be used.
If you cannot overload previously defined objects then the ability to include config files becomes FAR less useful imho. -Dave Rawks
On Tue, 2011-11-08 at 11:39 -0800, Dave Rawks wrote:
Sorry if this is a duplicate, I'm not sure it made it to the list on my first try...
commit b061328b3e0d3b466ac29ef4e1b3ee384b7130b0 Author: Balazs Scheidler <bazsi at balabit.hu> Date: Mon Oct 31 16:33:32 2011 +0100
configuration: report duplicate configuration elements
Previously if a configuration element name was used twice, the 2nd would be used and some memory was leaked on every reload.
This patch changes that by reporting duplicate IDs as configuration errors.
A patch was posted by Anthony, but a different implementation was used instead.
Reported-By: anthony lineham <anthony.lineham at alliedtelesis.co.nz> Signed-off-by: Balazs Scheidler <bazsi at balabit.hu>
Does this patch break the behavior described in the documentation for 3.3.1?
If an object is defined twice (for example the original syslog-ng configuration file and the file imported into this configuration file both define the same option, source, or other object), then the object that is defined later in the configuration file will be effective. For example, if you set a global option at the beginning of the configuration file, and later include a file that defines the same option with a different value, then the option defined in the imported file will be used.
If you cannot overload previously defined objects then the ability to include config files becomes FAR less useful imho.
uhm, uhm. Yes it does. I didn't know this was a documented feature :) This could be controlled (possibly by a configuration variable), but before I do that could you explain your usecase, which makes include files to be less useful? thanks. -- Bazsi
On 11/09/2011 12:38 PM, Balazs Scheidler wrote:
Does this patch break the behavior described in the documentation for 3.3.1?
If an object is defined twice (for example the original syslog-ng configuration file and the file imported into this configuration file both define the same option, source, or other object), then the object that is defined later in the configuration file will be effective. For example, if you set a global option at the beginning of the configuration file, and later include a file that defines the same option with a different value, then the option defined in the imported file will be used.
If you cannot overload previously defined objects then the ability to include config files becomes FAR less useful imho.
uhm, uhm. Yes it does. I didn't know this was a documented feature :)
This could be controlled (possibly by a configuration variable), but before I do that could you explain your usecase, which makes include files to be less useful?
Well, the standard case for having includes would be for use in distribution packaging. Where syslog-ng would ship with a default configuration and would then do an include against a directory of files, a "conf.d" style setup. Later other packages could drop bits of configuration into conf.d. Lets say you install some theoretical log collection and parsing application via a distribution provided package. Previously when overloading was supported that new package could drop a config chunk which overloads a "log object" from the default config so that now instead of outputting to a file it outputs to a destination object defined in this new config. Actually I was assuming that not only would this behavior persist into future versions of syslog-ng but I had also hoped that it would be enhanced to allow for things like partial overloads or concatenation of existing object definitions such as is available in software such as nagios. Since there is no function by which later defined objects can interrogate the state of earlier objects nor is there any capability for conditional object definition (afaik) there is some inherint limitation to the complexity of the configs which could be generated still, but this would be a huge step forward in config flexibility. ------Separate but related thought ;) Speaking of which, it would be nice if there was some method of bundling objects together. So that for instance you could define:
source s_local { internal(); unix-dgram("/dev/log"); file("/proc/kmsg" program-override("kernel") flags(kernel)); }; source s_remote { syslog( transport("udp") so_rcvbuf(16777216) ); }; source s_everything { source(s_local) source(s_remote) ); };
I might be missing something, but afaict there is no easy method to do such a definition in the documentation. -Dave Rawks
On Wed, 2011-11-09 at 14:58 -0800, Dave Rawks wrote:
On 11/09/2011 12:38 PM, Balazs Scheidler wrote:
Does this patch break the behavior described in the documentation for 3.3.1?
If an object is defined twice (for example the original syslog-ng configuration file and the file imported into this configuration file both define the same option, source, or other object), then the object that is defined later in the configuration file will be effective. For example, if you set a global option at the beginning of the configuration file, and later include a file that defines the same option with a different value, then the option defined in the imported file will be used.
If you cannot overload previously defined objects then the ability to include config files becomes FAR less useful imho.
uhm, uhm. Yes it does. I didn't know this was a documented feature :)
This could be controlled (possibly by a configuration variable), but before I do that could you explain your usecase, which makes include files to be less useful?
Well, the standard case for having includes would be for use in distribution packaging. Where syslog-ng would ship with a default configuration and would then do an include against a directory of files, a "conf.d" style setup. Later other packages could drop bits of configuration into conf.d. Lets say you install some theoretical log collection and parsing application via a distribution provided package. Previously when overloading was supported that new package could drop a config chunk which overloads a "log object" from the default config so that now instead of outputting to a file it outputs to a destination object defined in this new config.
It is possible to create a catch-all log statement, where source definitions need not be listed explicitly, e.g. source aaa {}; source bbb {}; destination foo {}; log { destination(foo); flags(catch-all); }; This would direct syslog-ng to process all messages, regardless of the source. Also, conf.d style inclusion is supported since 3.0; so I would say that distribution specific configuration can be implemented on what is available right now.
Actually I was assuming that not only would this behavior persist into future versions of syslog-ng but I had also hoped that it would be enhanced to allow for things like partial overloads or concatenation of existing object definitions such as is available in software such as nagios. Since there is no function by which later defined objects can interrogate the state of earlier objects nor is there any capability for conditional object definition (afaik) there is some inherint limitation to the complexity of the configs which could be generated still, but this would be a huge step forward in config flexibility.
I understand what you mean, and I can imagine some use-cases, however I still have my doubts that such a universal configuration file can be created for syslog-ng that would include all possible needs so that a package would only need to drop its own 'log definition' to interoperate with that. My vision right now is to create SCL blocks to cover applications, that would: 1) encapsulate all parameters required to track the logs of a given application 2) would make it very easy to create a syslog-ng configuration file that uses these blocks But otherwise how logs are processed are up to the user to specify. Something along the lines of: block source proftpd log_dir("/var/log/proftpd") { file("`log_dir`/transfer.log" follow-freq(1) tags('proftpd-transfer')); } source s_local { system(); proftpd(); ... }; E.g. instead of requiring a rigid structure in the configuration file and then allow "plugins" to augment that with minor stuff, I'd like to allow the admin (or the log management product using syslog-ng as a transport) to create the processing rules she wants but still make it relatively easy to pull in logs from various applications. If we have an agent-like setup (e.g. pull logs from all applications and send them to a central server/relay), you'd need something like: source s_local { system(); app1(); app2(); app3(); }; destination d_network { ... }; log { source(s_local); destination(d_network); }; However on the server, you'll most probably want something completely different: source s_network { syslog(); }; log { source(s_network); log { filter(f_app1); parser(f_app1); destination(d_app1); }; log { filter(f_app2); parser(f_app2); destination(d_app2); }; }
------Separate but related thought ;)
Speaking of which, it would be nice if there was some method of bundling objects together. So that for instance you could define:
source s_local { internal(); unix-dgram("/dev/log"); file("/proc/kmsg" program-override("kernel") flags(kernel)); }; source s_remote { syslog( transport("udp") so_rcvbuf(16777216) ); }; source s_everything { source(s_local) source(s_remote) ); };
I might be missing something, but afaict there is no easy method to do such a definition in the documentation.
You can't do this right now, except with catch-all, and using embedded log statements (like in the example above). I still can be convinced though, but could you explain how your "stock" config would like, and how a package like proftpd would drop a config snippet in the directory to "automatically" extend the local configuration? And how the same would work in an agent / server like setup? I'm almost convinced to remove the error message about this case though, even though I think that in most cases it is really an unintended config error. z -- Bazsi
On Sat, 2011-11-12 at 17:51 +0100, Balazs Scheidler wrote:
On Wed, 2011-11-09 at 14:58 -0800, Dave Rawks wrote:
On 11/09/2011 12:38 PM, Balazs Scheidler wrote:
Does this patch break the behavior described in the documentation for 3.3.1?
If an object is defined twice (for example the original syslog-ng configuration file and the file imported into this configuration file both define the same option, source, or other object), then the object that is defined later in the configuration file will be effective. For example, if you set a global option at the beginning of the configuration file, and later include a file that defines the same option with a different value, then the option defined in the imported file will be used.
If you cannot overload previously defined objects then the ability to include config files becomes FAR less useful imho.
uhm, uhm. Yes it does. I didn't know this was a documented feature :)
This could be controlled (possibly by a configuration variable), but before I do that could you explain your usecase, which makes include files to be less useful?
Well, the standard case for having includes would be for use in distribution packaging. Where syslog-ng would ship with a default configuration and would then do an include against a directory of files, a "conf.d" style setup. Later other packages could drop bits of configuration into conf.d. Lets say you install some theoretical log collection and parsing application via a distribution provided package. Previously when overloading was supported that new package could drop a config chunk which overloads a "log object" from the default config so that now instead of outputting to a file it outputs to a destination object defined in this new config.
It is possible to create a catch-all log statement, where source definitions need not be listed explicitly, e.g.
source aaa {}; source bbb {};
destination foo {};
log { destination(foo); flags(catch-all); };
This would direct syslog-ng to process all messages, regardless of the source.
Also, conf.d style inclusion is supported since 3.0; so I would say that distribution specific configuration can be implemented on what is available right now.
Actually I was assuming that not only would this behavior persist into future versions of syslog-ng but I had also hoped that it would be enhanced to allow for things like partial overloads or concatenation of existing object definitions such as is available in software such as nagios. Since there is no function by which later defined objects can interrogate the state of earlier objects nor is there any capability for conditional object definition (afaik) there is some inherint limitation to the complexity of the configs which could be generated still, but this would be a huge step forward in config flexibility.
I understand what you mean, and I can imagine some use-cases, however I still have my doubts that such a universal configuration file can be created for syslog-ng that would include all possible needs so that a package would only need to drop its own 'log definition' to interoperate with that.
My vision right now is to create SCL blocks to cover applications, that would: 1) encapsulate all parameters required to track the logs of a given application 2) would make it very easy to create a syslog-ng configuration file that uses these blocks
But otherwise how logs are processed are up to the user to specify.
Something along the lines of:
block source proftpd log_dir("/var/log/proftpd") {
file("`log_dir`/transfer.log" follow-freq(1) tags('proftpd-transfer'));
}
source s_local { system(); proftpd(); ... };
E.g. instead of requiring a rigid structure in the configuration file and then allow "plugins" to augment that with minor stuff, I'd like to allow the admin (or the log management product using syslog-ng as a transport) to create the processing rules she wants but still make it relatively easy to pull in logs from various applications.
If we have an agent-like setup (e.g. pull logs from all applications and send them to a central server/relay), you'd need something like:
source s_local { system(); app1(); app2(); app3(); };
destination d_network { ... };
log { source(s_local); destination(d_network); };
However on the server, you'll most probably want something completely different:
source s_network { syslog(); };
log { source(s_network); log { filter(f_app1); parser(f_app1); destination(d_app1); }; log { filter(f_app2); parser(f_app2); destination(d_app2); }; }
------Separate but related thought ;)
Speaking of which, it would be nice if there was some method of bundling objects together. So that for instance you could define:
source s_local { internal(); unix-dgram("/dev/log"); file("/proc/kmsg" program-override("kernel") flags(kernel)); }; source s_remote { syslog( transport("udp") so_rcvbuf(16777216) ); }; source s_everything { source(s_local) source(s_remote) ); };
I might be missing something, but afaict there is no easy method to do such a definition in the documentation.
You can't do this right now, except with catch-all, and using embedded log statements (like in the example above).
I still can be convinced though, but could you explain how your "stock" config would like, and how a package like proftpd would drop a config snippet in the directory to "automatically" extend the local configuration? And how the same would work in an agent / server like setup?
I'm almost convinced to remove the error message about this case though, even though I think that in most cases it is really an unintended config error.
I've committed this patch for the time being (before 3.3.2): commit c94867c78a3250795806a4b0eab69ea6be758c21 Author: Balazs Scheidler <bazsi@balabit.hu> Date: Sat Nov 12 20:46:22 2011 +0100 configuration: allow configuration object duplicates Historically syslog-ng used to allow overriding configuration block simply by defining the same object twice. A previous patch has changed this to an error, however there seem to be people who rely on the old behaviour. In order to serve both groups of people (who get it wrong and who really wants to use this) a new global variable has been introduced. This line in the beginning of the config: @define allow-config-dups 1 will restore the old behaviour, this is also printed to the console at startup. Reported-By: Dave Rawks <dave@pandora.com> Signed-off-by: Balazs Scheidler <bazsi@balabit.hu> -- Bazsi
On Mon, 2011-09-19 at 01:49 +0200, Jakub Jankowski wrote:
Hi,
I think I'm having a memleak in 3.3's HEAD. My production system, which receives ~300 messages/s throughout the day (so ~26.4 million messages daily) leaks ~700MB of memory per day.
Fix posted in a separate email, but can I ask if syslog-ng runs fine apart from the leak? That information would be very useful too. Thanks. -- Bazsi
Tuesday 27 of September 2011 20:17:21 Balazs Scheidler napisał(a):
On Mon, 2011-09-19 at 01:49 +0200, Jakub Jankowski wrote:
Hi,
I think I'm having a memleak in 3.3's HEAD. My production system, which receives ~300 messages/s throughout the day (so ~26.4 million messages daily) leaks ~700MB of memory per day.
Fix posted in a separate email, but can I ask if syslog-ng runs fine apart from the leak? That information would be very useful too.
Thanks for the fix, I'll try to see how it influences my syslog-ng memory usage as soon as I'll build new el5 package. Apart from that leak, I had some performance issues, but I can't blame those just on syslog-ng, they were rather a product of slow I/O, $lots of symlinks and perhaps some misconfiguration on my side. Not sure which, because in a "last resort" move I decided to change my use case. :) Performance and leak aside, it seems to work fine. Or perhaps I'm yet to learn the hard way it doesn't ;-) I'll report back if leaks I'm seeing now are gone, thanks again. BTW, any plans for 3.3.0beta3? :) -- Jakub Jankowski|shasta@toxcorp.com|http://toxcorp.com/ GPG: FCBF F03D 9ADB B768 8B92 BB52 0341 9037 A875 942D
participants (7)
-
anthony lineham
-
Balazs Scheidler
-
Christopher Barry
-
Dave Rawks
-
Gergely Nagy
-
Girish-Agarwal
-
Jakub Jankowski